Welcome to the MMU-RAG competition! This page contains everything you might need to start building and submitting your system for the text-to-video track.
Resources
Once a team is registered the organizers will contact you on their registered email (preferably gmail) and will be assigning the following items.
- Team ID
- ECR Repository ARN
- AWS ECR access keys
- S3 bucket name and region
- Port Number where the API needs to run
- Clueweb 22 API key (if requested)
- Participants can request the Clueweb 22 API key later in the competition too!
Validation Set
To support the development and debugging of your models, we are releasing a validation set for the Text-to-Video track:
The validation set consists of a small number of example queries and their gold text references. This set is meant to help teams test their pipelines and ensure compatibility with our evaluation format before final submission.
Note: Validation sets are not used in the final evaluation and are safe to use for model tuning and format debugging.
Each line in the validation set is a JSON object with the following fields:
query(string): The user’s information-seeking question.reference(string): A gold reference response that accurately and completely answers the query. This can be used for tuning or evaluation with automatic metrics such as ROUGE or BERTScore.iid(string): A unique instance identifier. This can be used to track and match outputs in your system.
Starter Code
We provide a modular starter code template to help you build your RAG system efficiently. The codebase is structured with separate components for each stage of the pipeline, making it easy to experiment and iterate.
Starter Code File: https://github.com/AGI-LTI/MMU-RAG-Starter/blob/main/Text-to-Video/submission_starter_video.py
Generated Video Specifications
We expect the generated videos for each query to be 5-6 seconds in duration.
FineWeb Search API
Base URL:https://clueweb22.us/fineweb/search
Authentication
All requests must include an API key:
x-api-key: <YOUR_FINEWEB_API_KEY>
Your API key will be sent to you after team registration.
HTTP Request
GET https://clueweb22.us/fineweb/search
Query Parameters:
| Name | Type | Required | Description |
|---|---|---|---|
query |
string | yes | The search query string |
k |
integer | yes | Number of documents to return |
Response Format:
{
"results": [Base64-encoded JSON documents]
}
ClueWeb-22 Search API Access
Base URL:https://clueweb22.us/search
Authentication
All requests must include an API key:
x-api-key: <YOUR_RETRIEVER_API_KEY>
Your API key will be sent to you after your ClueWeb application is approved.
HTTP Request
GET https://clueweb22.us/search
Query Parameters:
| Name | Type | Required | Description |
|---|---|---|---|
query |
string | yes | The search query string |
k |
integer | yes | Number of documents to return |
cw22_a |
boolean | no | Use ClueWeb22-A instead of default ClueWeb22-B |
Submission Requirements and Formats
We require your submission to fulfil the following requirements for us to perform static and dynamic evaluation:
-
Complete the
retrieverfunction in the starter code -
Complete the
generatorfunction in the starter code
⚠️ Important Note: The live RAG-Arena can be accessed by multiple users simultaneously. Please ensure your submission is designed to handle at least 10-15 concurrent requests efficiently and reliably.
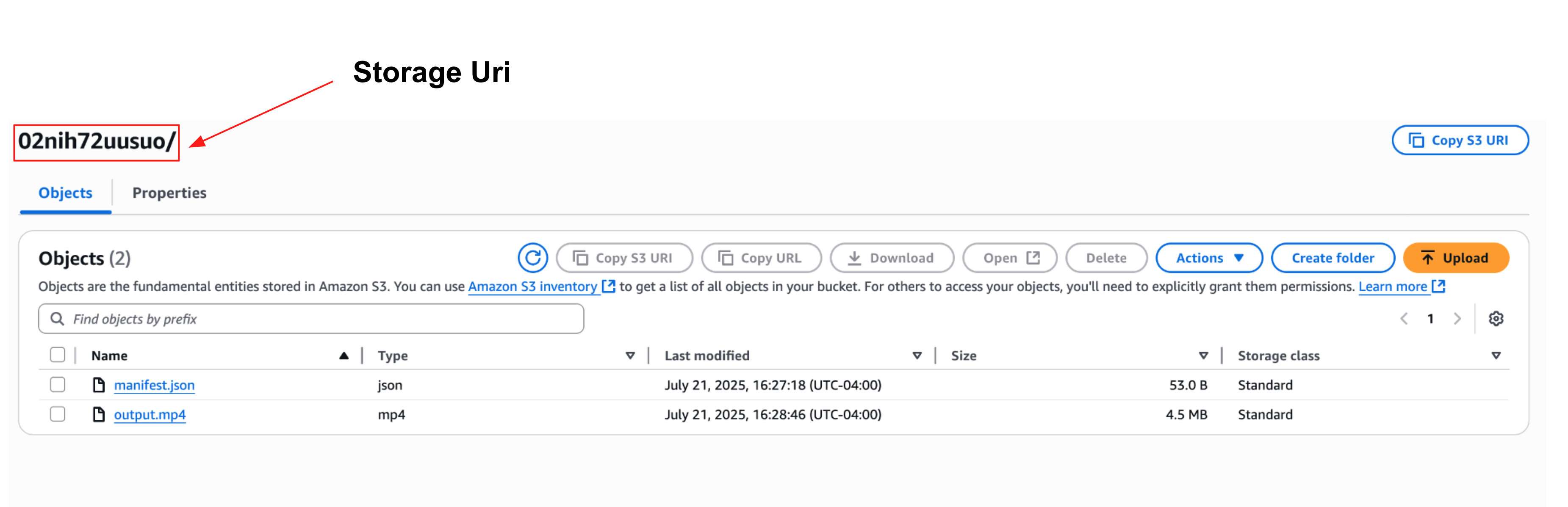
The main backend has a single endpoint generate-video that returns the s3-Storage URI, the region of the s3 bucket (where the video is stored) and retrieved docs along with some metadata like the status and the error message.
1. Retriever
class RetrieverResponse(TypedDict):
status: str
error: Optional[str]
retrieved_docs: List[str]
def retriever(question) -> RetrieverResponse:
"""
To be filled by the Partipant. Ideally we expect the participant to retrive top -k documents with each document of String datatype
as an element of the list.
Returns a dictionary
{
"status" : "error" OR "success
"error" : "No documents retrieved" OR None
"retrieved_docs" : [] or retrieved document
}
"""
return {
"status" : "success",
"error" : None,
"retrieved_docs" : ["document1", "document2", "document3"]
}
Participants are allowed to use any retriever implementation but they are expected to return a dictionary of the following keys:
| Key | Type | Description |
|---|---|---|
| Status | string | Must be either “error” or “success” |
| Error | string/None | An appropriate error message for debugging, or None if there is no error |
| Retrieved_docs | list | A Python list containing text from the retrieved documents, or an empty list if retrieval was unsucessfull |
2. Generator
class GeneratorResponse(TypedDict):
status : str
error : Optional[str]
s3_BUCKET_NAME : str
region : str
Storage_Uri : Optional[str]
def generator(retrieved_docs, question) -> GeneratorResponse:
"""
To be filled by the Partipant. We expect the particpants to generate a video and store it in an s3 bucket.
Returns a dictionary
{
"status" : "error" OR "success
"error" : Appropraite error message for any intermediate steps OR None
"s3_BUCKET_NAME" : The s3 bucket assigned to the team, this will be used an integrity check in the main backend
"Storage_Uri" : The storage Uri of the generated video in the assigned s3 bucket or None
}
"""
return {
"status" : "success",
"error" : None,
"s3_BUCKET_NAME" : "ragarena-videos",
"region" : "us-east-1",
"Storage_Uri" : "https://ragarena-videos.s3.amazonaws.com/video.mp4"
}
The generator function should return a dictionary with the following keys:
| Key | Type | Description |
|---|---|---|
| status | string | Must be either “error” or “success” |
| Error | string/None | An appropriate error message for debugging, or None if there is no error |
| s3_BUCKET_NAME | string | The name of the s3 bucket assigned to the team |
| region | string | AWS region of the s3 bucket |
| Storage Uri | string | The s3 Object id under which the output video is stored |
The generator or the text-to-video model can be either an open-source text-to-video model or an API call. The core backend infrastructure of the Arena platform expects the generated video to be stored in a dedicated S3 Bucket (that is assigned to participants on registration) and expects the generated output to be named output.mp4.
###
3. Dockerizing Your System
FROM python:3.11-slim
# Set working directory
WORKDIR /app
# Copy requirements first to leverage Docker cache
COPY requirements.txt .
# Install system dependencies
RUN apt-get update && apt-get install -y \
postgresql-client \
libpq-dev \
&& rm -rf /var/lib/apt/lists/*
# Install Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy application code (includes .env file)
COPY . .
# Expose port
EXPOSE 4001
# FastAPI (ASGI)
CMD ["gunicorn", "video_baseline:app", "-w", "2", "-k", "uvicorn.workers.UvicornWorker", "--bind", "0.0.0.0:4001", "--timeout", "2000"]
Submission Options:
- Static Submission Guidelines - Option 1: Static evaluation on validation set (non-cash prizes)
- Full System Submission Guidelines - Option 2: Complete system submission (main competition, cash prizes)